Introduction
It's really fun to create your own tools. With some extra time on my hands this weekend, I decided to work on building a small tool that would solve a problem i'd been facing for some time - converting wikilinks to relative links.
For those who are unaware, when you work in tools like Obsidian, the default tends to be wikilinks that look like this [[wiki-link]]. This is great if you're only using obsidian but limits the portability of your markdown script itself. For platforms such as Github, the lack of absolute links means that you can't easily click and navigate between markdown files on their web platform.
So, with that in mind, I thought I would give Rust a spin. My brief idea was quite simple
- Iterate through all the files in a given directory and find all of the relevant markdown files.
- Generate a mapping of markdown file names to their relative path
- For each of these files, use a regex to identify any potential wikilinks
- For each wikilink, replace it with its absolute path (relative to the root directory)
Getting the cli args
After doing a bit of googling, I realised that there was a library calledclap which I could use to parse user arguments. An extra bonus was that you could represent user cli args as named inputs
use clap::Parser;
#[derive(Parser)]
struct Cli {
root_dir: String,
#[clap(long, short, use_value_delimiter = true)]
ignore_dirs: Vec<String>,
}
::parse method that was defined on the Parser. This allows for an easy call of
use clap::Parser;
#[derive(Parser)]
struct Cli {
root_dir: String,
#[clap(long, short, use_value_delimiter = true)]
ignore_dirs: Vec<String>,
}
fn main(){
let args = Cli::parse();
let canonical_root_dir = std::fs::canonicalize(&args.root_dir).unwrap();
let canonical_root_dir_string = canonical_root_dir.to_str().unwrap();
}
cargo run as
cargo run ../../ML-notes --ignore-dirs .obsidian,.git,assetsNote too that we convert any relative paths that the user might have given us into a canonical path so that we can use an absolute path to navigate through the directory itself. This has an added advantage of catching any potential mispellings of folders/paths that the user might have made.
Verifying if we have a valid file/folder
One of the most important parts of this specific cli is the ability to ignore certain folders that we can pass in using theignore-dirs cli-flag. To do so, we can write a few simple tests that capture this functionality. Note here that I've opted to check is something is invalid using the is_invalid_path function itself.
- We want to verify that markdown files and folders are going to be marked as valid files => return false
- We want to verify that ignored folders are marked as invalid => return true
- We want to verify that files in ignored folders are marked as invalid
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn test_valid_markdown_file() {
let path = Path::new("example.md");
let ignore_dirs = vec!["temp".to_string()];
assert!(!is_invalid_path(path, &ignore_dirs));
}
#[test]
fn test_invalid_non_markdown_file() {
let path = Path::new("example.txt");
let ignore_dirs = vec!["temp".to_string()];
assert!(is_invalid_path(path, &ignore_dirs));
}
#[test]
fn test_ignored_directory_file() {
let path = Path::new("temp/example.md");
let ignore_dirs = vec!["temp".to_string()];
assert!(is_invalid_path(path, &ignore_dirs));
}
#[test]
fn test_ignored_directory() {
let path = Path::new("./fixtures/ignored_dir");
let ignore_dirs = vec!["ignored_dir".to_string()];
assert!(is_invalid_path(path, &ignore_dirs));
}
#[test]
fn test_non_ignored_directory() {
let path = Path::new("./src");
let ignore_dirs = vec!["temp".to_string()];
assert!(!is_invalid_path(path, &ignore_dirs));
}
}We can run these tests ( all should fail since we haven't implemented the function at all )
cargo test I ended up implementing this check with this function
fn is_invalid_path(path: &Path, ignore_dirs: &Vec<String>) -> bool {
let path_str = path.to_string_lossy();
let is_dir = path.is_dir();
let ends_with_md = path_str.ends_with(".md");
let is_valid_dir_or_file = is_dir || ends_with_md;
!is_valid_dir_or_file
|| ignore_dirs
.iter()
.any(|ignore_dir| path_str.contains(ignore_dir))
}
is_dir method on paths that we can use to check for directories. We then use a simple iterator over the ignore_dirs to check if a file should be ignored.
Getting all Paths
Now that we've got a simple function which can check whether a file should be processed given it's path, let's start writing our iterators to fix our path. Remember here that our final desired product is a mapping of the file name ( which is how the wiki link would store information on the file itself ) to a path that we can convert into a canonical path itself.
fn retrieve_record(
path: &Path,
mut acc: HashMap<String, String>,
ignore_dirs: &Vec<String>,
) -> Result<HashMap<String, String>, String> {
if is_invalid_path(path, ignore_dirs) {
return Ok(acc);
}
if path.is_file() {
let mut new_acc = acc.clone();
new_acc.insert(
path.file_stem().unwrap().to_string_lossy().to_string(),
path.to_string_lossy().to_string(),
);
return Ok(new_acc);
}
let entries = fs::read_dir(path).map_err(|err| err.to_string())?;
for entry in entries {
let entry = entry.map_err(|err| err.to_string())?;
acc = retrieve_record(&entry.path(), acc, ignore_dirs)?;
}
Ok(acc)
}
.fold to work the way I wanted to and acc was made immutable by default. I'm not sure whether this might be a good practice either to be honest. I tried to get around this issue by using a mut new_acc variable but on hindsight perhaps an easier method might have been to make the acc itself mutable and not repeatedly clone it.
Regex!
Now that we've got the mapping that we wanted, we can use a simple regex to identify wikilinks. In my case, this worked pretty well . Note that you'll need to add theregex crate in order for this to work nicely.
use regex;
let re = regex::Regex::new(r"\[\[(.*?)\]\]").expect("Failed to compile regex");.collect function.
let file_list: Vec<String> = mapping.values().cloned().collect();
vec of file paths that we've already identified as valid paths. We can then iterate over this list by converting our .vec into a iterator.
for file in file_list.iter() {
// Logic Goes Here
}Once we have the file path itself, we can then read in the file content and use the regex to match and see if it has any wiki links we can replace.
let file_path = std::fs::canonicalize(file).unwrap();
let relative_path_to_root_dir = file_path
.to_str()
.unwrap()
.replace(&canonical_root_dir_string, "");
let file_content = fs::read_to_string(&file_path).expect("Failed to read file");re.captures_iter method.
for cap in re.captures_iter(&file_content) {
// Do processing here
}For each wikilink, we can then replace it with the following logic
if let Some(file_path_in_mapping) = mapping.get(&cap[1]) {
let mapping_file_path = std::fs::canonicalize(file_path_in_mapping).unwrap();
let sanitized_mapping_file_path = mapping_file_path
.to_str()
.unwrap()
.replace(canonical_root_dir_string, "")
.replace(" ", "%20");
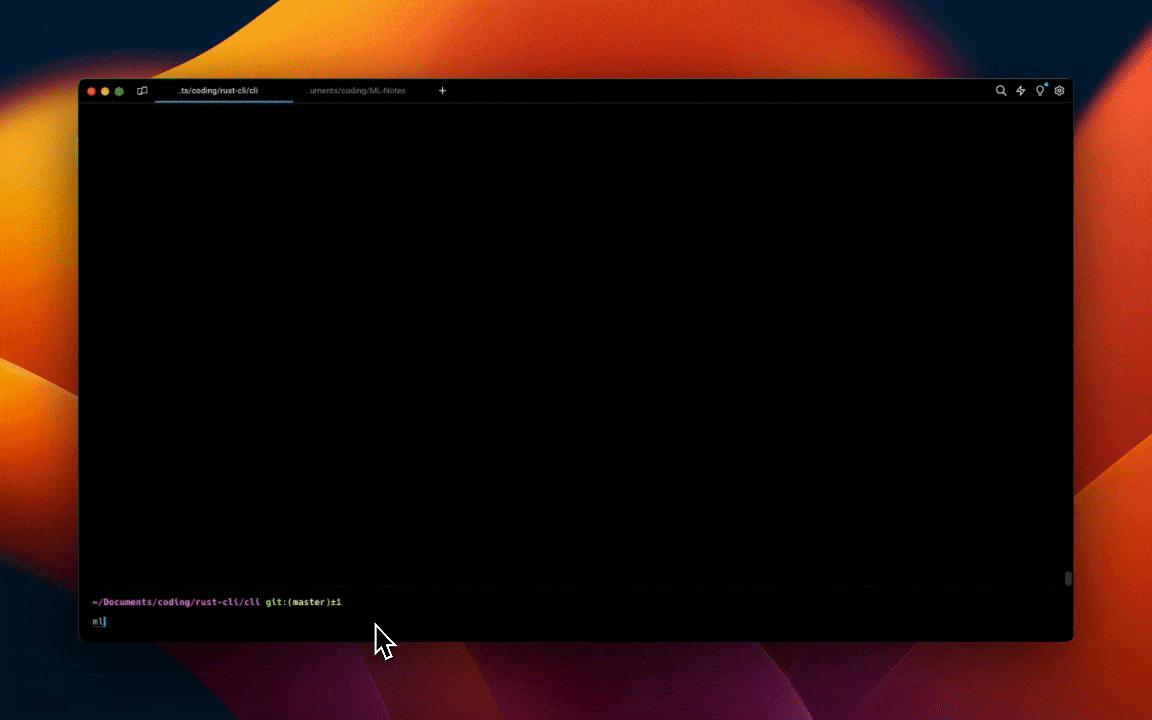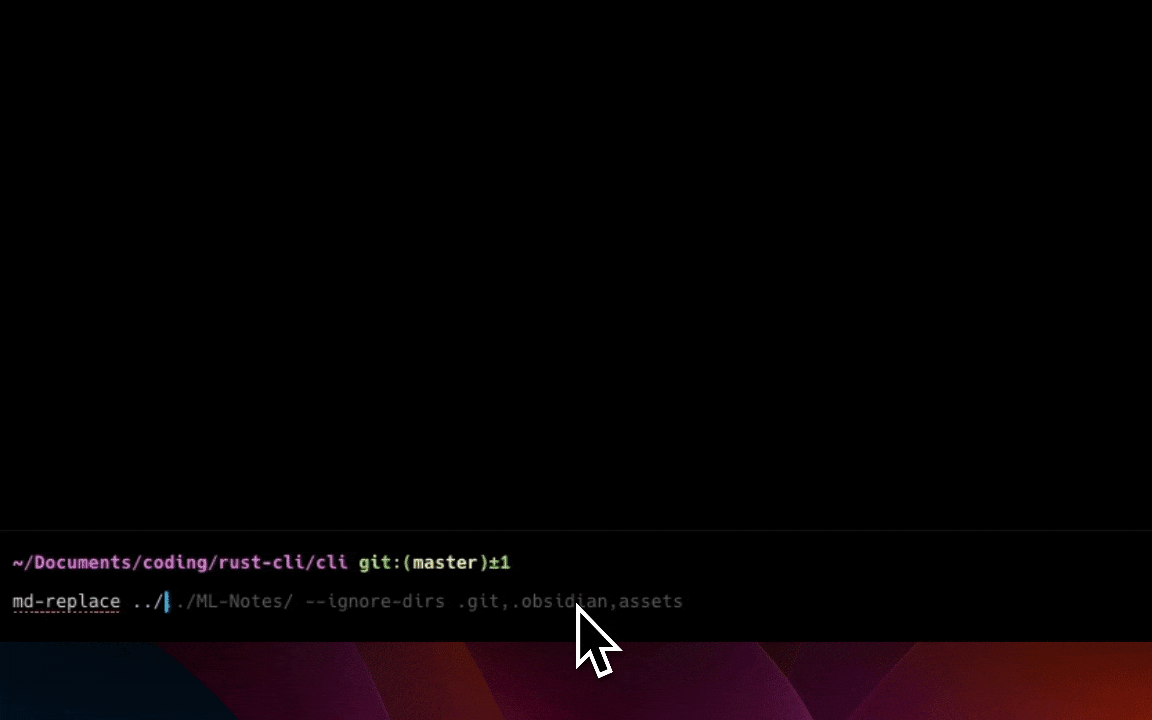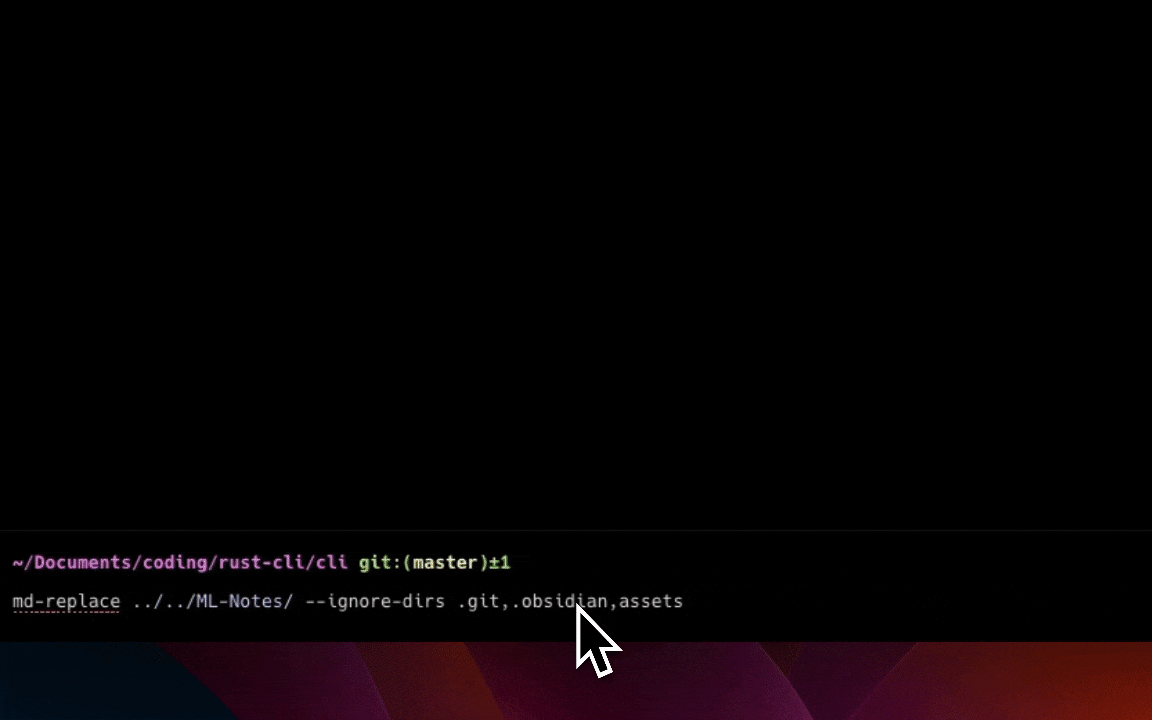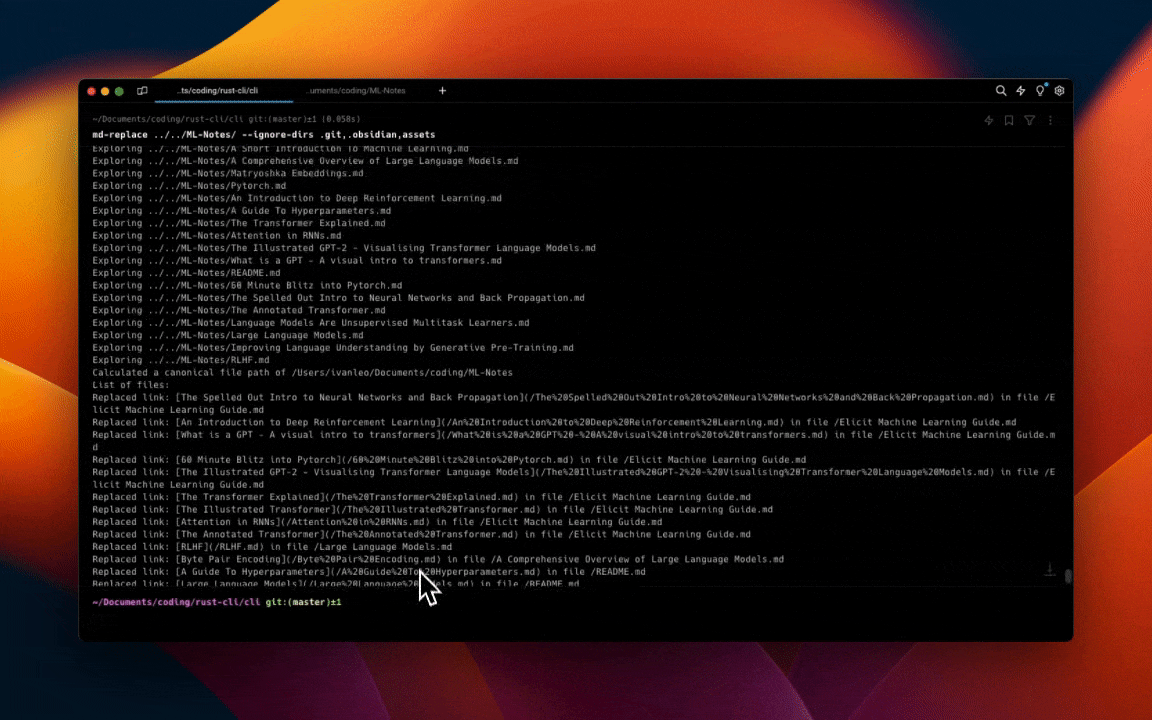
let new_link = format!("[{}]({})", &cap[1], sanitized_mapping_file_path);
println!(
"Replaced link: {} in file {}",
new_link, relative_path_to_root_dir
);
let original_file_content =
fs::read_to_string(file).expect("Failed to read file for replacement");
let replaced_content = original_file_content.replace(&cap[0], &new_link);
fs::write(file, replaced_content)
.expect("Failed to write replaced content to file");
}.replace call, making sure to use escape the spaces with the %20 character.